-
Created by
 Michael Brand on Oct 05, 2014
4 minute read
Michael Brand on Oct 05, 2014
4 minute read
The fragmentation mechanism in Odysseus
The fragmentation mechanism is part of the Peer-Feature and can increase the performance of a distributed query processing in a Peer-to-Peer network of Odysseus instances. Currently, the primary horizontal fragmentation (round robin, hash and range) is provided. Figure 1 shows a simplified operator graph. All operators between sources and sinks are replicated several times. A Fragment operator splits the data stream into several, disjunctive partial streams (fragments). Therefore, each replica gets just a fraction of the complete data stream for processing and each replica produces a different result stream. To merge the different result streams, a Union operator is inserted.

Typically, fragments are to be processed on different peers in order to reduce the load for each peer. A normal, not simplified operator graph for the same query as in figure 1 is shown in figure 2. Here, special JxtaSender and JxtaReceiver operators handle the transport of data stream elements from one peer to another.
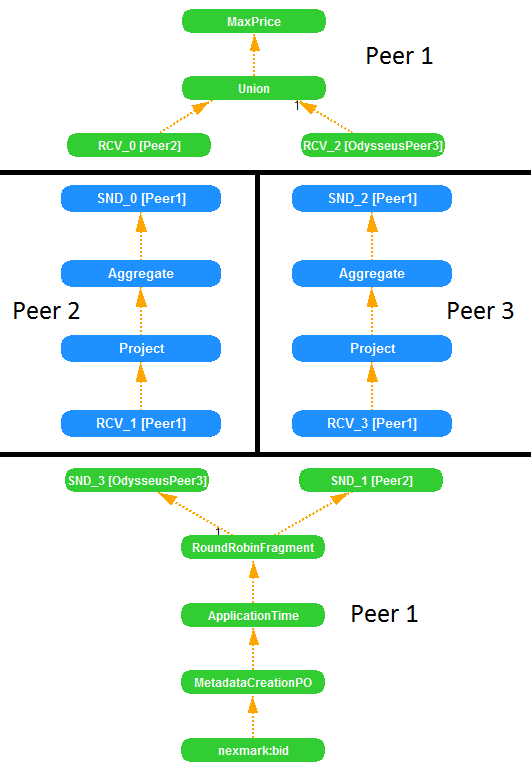
A query partitioning provides the basis for the fragmentation mechanism. The partitioning of a query means the creation of disjunctive partial queries with the objective to determine those operators, which shall be executed on the same peer. In figure 1 and figure 2 a partition strategy was used, which creates one single partial query with all operators.
Due to the characteristics of different operators, not every operator can be part of a fragment. By no means exhaustive those operators are ElementWindow, Aggregate, FastMedian, and TupleAggregate. The fragmentation mechanism will exclude those operators. More concrete, the data streams will be merged before them and split again after them.
Note that a hash fragmentation can help to use aggregations within fragments. It will be explained below.
The activation of fragmentation via Odysseus Script
The user can enable the fragmentation mechanism via Odysseus Script. Listing 1 shows the query definition in PQL (with Odysseus Script) for the query shown in figure 2. At first, the query distribution has to be enabled. After that, a series of distribution commands follow: The partition strategy defines the partial queries as described above (QueryCloud creates one partial query containing all operators). The modification command enables the fragmentation (concrete the round robin fragmentation). The first additional argument is the source, which data stream shall be fragmented, and the second argument is the degree of fragmentation (how many fragments). The last distribution command (allocation) defines which peer executes which partial query (here, roundrobin is a simple, well known strategy). The PQL query itself has not to be changed to enable fragmentation (e.g., no need to insert a Fragment operator manually).
#PARSER PQL
#CONFIG distribute true
#PEER_PARTITION QUERYCLOUD
#PEER_MODIFICATION FRAGMENTATION_HORIZONTAL_ROUNDROBIN nexmark:bid 2
#PEER_ALLOCATE ROUNDROBIN
#ADDQUERY
proj = PROJECT({
attributes=['auction', 'price']
}, nexmark:bid)
max = AGGREGATE({
aggregations=[['max', 'price', 'maxPrice']],
group_by=['auction']
}, proj)
out = SINK({
Sink='MaxPrice'
}, max)
The round robin fragmentation
The usage of the round robin fragmentation is already shown in listing 1 and the routing algorithm is outport = k mod n with k as the current element counting and n as the number of fragments.
The hash fragmentation
The usage of the hash fragmentation is shown in listing 2.
#PEER_MODIFICATION FRAGMENTATION_HORIZONTAL_HASH nexmark:bid 2 auction
The shown line replaces the corresponding line in listing 1. As an optional additional argument a hash key consisting of one or more attributes can be specified (e.g., auction). The routing algorithm is outport = h mod n with h as the hash code generated from the hash key and n as the number of fragments. If no hash keys are given, all attributes are considered for h.
The hash fragmentation with the usage of hash keys can enable aggregations (Aggregate, FastMedian, and TupleAggregate) to be part of fragments, if the grouping attributes are used as hash key.
The range fragmentation
The usage of the range fragmentation is shown in listing 3.
#PEER_MODIFICATION FRAGMENTATION_HORIZONTAL_RANGE nexmark:bid.price 50
The shown line replaces the corresponding line in listing 1. In a different way from the other fragmentation algorithms, the given source of fragmentation must be a full quantified attribute. It determines the attribute, for which ranges shall be used. All other arguments define those ranges as lower bounds and the number of these lower bounds + 1 is the number of fragments. For example, "nexmark:bid.price 50" means to build ranges for the attribute price. The only lower bound is 50 resulting in two fragments. The first fragment is for all elements, having price >= 50. All other elements are routed to the second fragment.
Partial fragmentation
Besides the fragmentation of a complete query (more exactly of one source stream), the user can decide to fragment just a substream. Listing 4 shows the query definition in PQL. It's the same query as in Listing 1 with the exception that the first argument for the fragmentation mechanism has changed. It now defines the start and end point of the fragmentation (the fragmentation will begin after the start and end before the end). Values for start and end can either be a source name (e.g., nexmark:bid; only allowed for start) or a unique ID of an operator.
#PARSER PQL
#CONFIG distribute true
#PEER_PARTITION QUERYCLOUD
#PEER_MODIFICATION FRAGMENTATION_HORIZONTAL_ROUNDROBIN [start,end] 2
#PEER_ALLOCATE ROUNDROBIN
#ADDQUERY
proj = PROJECT({
attributes=['auction', 'price'],
ID = 'start'
}, nexmark:bid)
max = AGGREGATE({
aggregations=[['max', 'price', 'maxPrice']],
group_by=['auction']
}, proj)
out = SINK({
Sink='MaxPrice',
ID = 'end'
}, max)