The Odysseus Procedural Query Language (PQL) – Usage and Extension
This document describes the basic concepts of the Procedural Query Language (PQL) of Odysseus, shows how to use and extend the language. In contrast to languages SQL based languages like the Continuous Query Language (CQL) or StreamSQL, PQL is more procedural and functional than declarative. The first part of this document is for users and shows how to formulate queries with PQL. The second part of the document is intended for developers who want to extend PQL.
Using PQL in Queries
PQL is an operator based language where an operator can be seen as a logical building block of the query. Thus, PQL is the connection of several operators. Since Odysseus differentiates between logical operators and their physical operators, which are the implementing counterpart, PQL is based upon logical operators. Therefore, it may happen that the query gets changed during the transformation from the logical query plan into the physical query plan. This includes also logical optimization techniques like the restructuring of the logical query plan. To avoid this, you can explicitly turn off the query optimization.
Define an Operator
An operator can be used in PQL via its name and some optional settings, which can be compared with a function and the variables for the function:
OPERATORNAME(parameter, operator, operator, ...)
The first variable (parameter) describes operator dependent parameters and is used for configuring the operator. Note, that there is only one parameter variable! The other variables (operator) are input operators, which are the preceding operators that push their data into this operator. The inputs of an operator can be directly defined by the definition of another operator:
OPERATOR1(parameter1, OPERATOR2(Parameter2, OPERATOR3(...)))
Except for source operators (usually the first operator of a query) each operator should have at least one input operator. Thus, the operator can only have parameters:
OPERATOR1(parameter1)
Accordingly, the operator may only have input operators but no parameters:
OPERATOR1(OPERATOR2(OPERATOR3(...)))
Alternatively, if the operator has neither parameters nor input operators, the operator only exists of its name (without any brackets!), so just:
OPERATORNAME
It is also possible to combine all kinds of definitions, for example:
OPERATOR1(OPERATOR2(Parameter2, OPERATOR3))
Intermediate Names, Views and Sources
Since the nesting of operators may lead to an unreadable code, it is possible to name operators to reuse intermediate result. This is done via the "=" symbol. Thus, we can temporary save parts of the query, for example:
Result2 = OPERATOR2(Parameter2, OPERATOR3)
The defined names can be used like operators, so that we can insert them as the input for another operator, for example:
Result2 = OPERATOR2(Parameter2, OPERATOR3)OPERATOR1(Result2)
There could be also more than one intermediate result, if they have different names:
Result1 = OPERATOR1(Parameter1, …)Result2 = OPERATOR2(Parameter2, Result1)Result3 = OPERATOR3(Parameter3, Result2)
And you can use the intermediate name more than one time, e.g. if there are two or more operators that should get the same preceding operator:
Result1 = OPERATOR1(Parameter1, …)OPERATOR2(Parameter2, Result1)OPERATOR3(Parameter3, Result1)
All intermediate results that are defined via the "=" are only valid within the query. Thus, they are lost after the query is parsed and runs. This can be avoided with views.
A view is defined like the previous described intermediate results but uses ":=" instead of "=", e.g.:
Result2 := OPERATOR2(Parameter2, OPERATOR3)
Such a definition creates an entry into the data dictionary, so that the view is globally accessible and can be also used in other query languages like CQL.
Alternatively, the result of an operator can also be stored as a source into the data dictionary by using "::="
Result2 ::= OPERATOR2(Parameter2, OPERATOR3)
The difference between a view and a source is the kind of query plan that is saved into the data dictionary and is reused. If a view is defined, the result of the operator is saved as a logical query plan, which exists of logical operators. Thus, if another query uses the view, the logical operators are fetched from the data dictionary and build the lower part of the new operator plan or query. If an operator is saved as a source, the result of the operator is saved as a physical query plan, which exists of already transformed and maybe optimized physical operators. Thus, reusing a source is like a manually query sharing where parts of two or more different queries are used together. Additionally, the part of the source is not recognized if the new part of the query that uses the source is optimized. In contrast, the logical query plan that is used via the a view is recognized, but will not compulsorily lead to a query sharing.
Finally, all possibilities gives the following structure:
QUERY = (TEMPORARYSTREAM | VIEW | SHAREDSTREAM)+ TEMPORARYSTREAM = STROM "=" OPERATOR VIEW = VIEWNAME ":=" OPERATOR SHAREDSTREAM = SOURCENAME "::=" OPERATOR
Parameters – Configure an Operator
As mentioned before, the definition of an operator can contain a parameter. More precisely, the parameter is a list of parameters and is encapsulated via two curly brackets:
OPERATOR({parameter1, paramter2, …}, operatorinput)
A parameter itself exists of a name and a value that are defined via a "=". For example, if we have the parameter port and want to set this parameter to the 1234, we use the following definition:
OPERATOR({port=1234}, …)
The value can be one of the following simple types:
- Integer or long:
OPERATOR({port=1234}, …)
- Double:
OPERATOR({possibility=0.453}, …)
- String:
OPERATOR({host='localhost'}, …)
Furthermore, there are also some complex types:
- Predicate: A predicate is normally an expression that can be evaluated and returns either true or false. In general, a predicate is defined by via a function with a string, e.g.:
OPERATOR({port=RelationalPredicte('1<1234')}, …)
(This example uses the RelationalPredicate, which also can be replaced by other predicates.)
- List:It is also possible to pass a list of values. For that, the values have to be surrounded with squared brackets:
OPERATOR({color=['green', 'red', 'blue']}, …)
(Type of elements: integer, double, string, predicate, list, map).
- Map: This one allows maps like the HashMap in Java. Thus, one parameter can have a list of key-value pairs, where the key and the value are one of the described type. So, you can use this, to define a set of pairs where the key and the value are strings using the "=" for separating the key from the value:
OPERATOR({def=['left'='green', 'right'='blue']}, …)
It is also possible that values are lists:
OPERATOR({def=['left'=['green','red'],'right'=['blue']]}, …)
Remember, although the key can be another data type than the value, all keys must have the same data type and all values must have the same data type
Notice, that all parameters and their types (string or integer or list or…) are defined by their operator. Therefore, maybe it is not guaranteed that the same parameters of different operators use the same parameter declaration – although we aim to uniform all parameters.
Ports – What if the Operator Has More Than One Output?
There are some operators that have more than one output. Each output is provided via a port. The default port is 0, the second one is 1 etc. The selection for example, pushes all elements that fulfill the predicate to output port 0 and all other to output port 1. So, if you want to use another port, you can prepend the port number with a colon in front of the operator. For example, if you want the second output (port 1) of the select:
PROJECT({…}, 1:SELECT({predicate=RelationalPredicate('1<x')}, …))
The Full Grammar of PQL
QUERY = (TEMPORARYSTREAM | VIEW | SHAREDSTREAM)+ TEMPORARYSTREAM = STREAM "=" OPERATOR VIEW = VIEWNAME ":=" OPERATOR SHAREDSTREAM = SOURCENAME "::=" OPERATOR OPERATOR = QUERY | [OUTPUTPORT ":"] OPERATORTYPE "(" (PARAMETERLIST [ "," OPERATORLIST ] | OPERATORLIST) ")" OPERATORLIST = [ OPERATOR ("," OPERATOR)* ] PARAMETERLIST = "{" PARAMETER ("," PARAMETER)* "}" PARAMETER = NAME "=" PARAMETERVALUE PARAMETERVALUE = LONG | DOUBLE | STRING | PREDICATE | LIST | MAP LIST = "[" [PARAMETERVALUE ("," PARAMETERVALUE)*] "]" MAP = "[" [MAPENTRY ("," MAPENTRY*] "]" MAPENTRY = PARAMETERVALUE "=" PARAMETERVALUE STRING = "'" [~']* "'" PREDICATE = PREDICATETYPE "(" STRING ")"
List of available PQL Operators
Odysseus has a wide range of operators build in and are explained here.
Base Operators
ACCESS
The access operator can be used to integrate new sources into odysseus. Further information can be found in the Documentation to the "Access Operator Framework".
AGGREGATE
Description
This operator is used to aggregate and group the input stream.
Parameter
group_by:An optional list of attributes over which the grouping should occur.aggregations:A list if elements where each element contains up to four string:- The name of the aggregate function, e.g. MAX
- The input attribute over which the aggregation should be done
- The name of the output attribute for this aggregation
- The optional type of the output
dumpAtValueCount:This parameter is used in the interval approach. Here a result is generated, each time an aggregation cannot be changed anymore. This leads to fewer results with a larger validity. With this parameter the production rate can be raised. A value of 1 means, that for every new element the aggregation operator receives new output elements are generated. This leads to more results with a shorter validity.
Example:
aggregated = aggregate({group_by = ['bidder'], aggregations=[ ['MAX', 'price', 'max_price', 'double'] ]}, windowed)
The set of aggregate functions is extensible. The following list is in the core Odysseus:
MAX: The maximum elementMIN: The minimum elementAVG: The average elementSUM: The sum of all elementsCOUNT: The number of elementsSTDDEV: The standard deviation
Some nonstandard aggregations: These should only be used, if you a familiar with them:
FIRST: The first elementLAST: The last elementNTH: The nth elementRATE:??
BUFFER
Description
Typically, Odysseus provides a buffer placement strategy to place buffers in the query plan. This operator allows adding buffers by hand. Buffers receives data stream elements and stores them in an internal elementbuffer. The scheduler stops the execution here for now. Later, the scheduler resumes to execution (e.g. with an another thread).
Parameter
Type:The type of the buffer. The following types are currently part of Odysseus:Normal:This is the standard type and will be used if the type parameter is absent- Currently, no further types are supported in the core Odysseus. In the future, there will be some buffers integrated to treat prioritized elements.
MaxBufferSize: If this value is set, a buffer will block if it reaches its maximal capacity. No values will be thrown away; this is not a load shedding operator!
Example
BUFFEREDFILTER
Description
This operator can be used to reduce data rate. It buffers incoming elements on port 0 for bufferTime and evaluates a predicate over the elements on port 1. If the predicate for the current element e evaluates to true, all elements from port 0 that are younger than e.startTimeStamp()-bufferTime will be enriched with e and delivered for deliverTime. Each time the predicate evaluates to true, the deliverTime will be increased.
Parameter
Predicate: The predicate that will be evaluated on element of port 1BufferTime:The time in history, the elements will be kept in historyDeliverTime:The time in the future, the elements will be delivered
Example
BufferedFilter({predicate = RelationalPredicate('id == 2 || id == 4 || id == 10'), bufferTime = 5000, deliverTime = 20000}, nexmark:bid2, nexmark:person2)
CALCLATENCY
Description
Odysseus has some features to measure the latency of single stream elements. This latency information is modeled as an interval. An operator in Odysseus can modify the start point of this interval. This operator sets the endpoint and determines the place in the query plan, where the latency measurement finds place. There can be multiple operators in the plan, to measure latency at different places.
Parameter
Example
CHANGEDETECT
Description
This operator can be used to filter out equal elements and reduce data rate.
Parameter
ATTR (List<String>): only these attribute are considered for the comparisonHeartbeatrate (Integer):For each nth element that is filtered out, a heartbeat is generated to state the progress of timedeliverFirstElement (Boolean):If true, the first element will be send to the next operator.
DIFFERENCE
Description
This operator calculates the difference between two input sets.
Parameter
None
Example
diff = difference(mapped, projected)
ENRICH
Description
This operator enriches tuples with information from the context store. Further Information: http://odysseus.offis.uni-oldenburg.de/twiki/bin/view/Main/ContextStore
Parameter
ATTRIBUTES:The attributes from the store object, that should be used for enrichmentSTORE:The name of the storeOUTER:
Example
EVENTTRIGGER
Description
Parameter
Example
EXISTENCE
Description
This operator tests an existence predicate and can be used with the type EXISTS (semi join) and NOT_EXISTS (anti semi join). The predicates can be evaluated against the element from the first input and the second input.
Semi join: All elements in the first input for which there are elements in the second input that fulfills the predicate are sent.
Semi anti join: All elements in the first input for which there is no element in the second input that fulfills the predicate are sent.
Parameter
PredicateType
Example
existencial = existence({type='EXISTS', predicate=RelationalPredicate('auction = auction_id')}, projected, renamed) existence({type='NOT_EXISTS', predicate=RelationalPredicate('auction = auction_id')}, projected, renamed)
FILESINK
Description
The operator can be used to dump the results of an operator to a file.
Parameter
FILE:The filename to dump. If the path does not exist it will be created.FILETYPE:The type of file, CSV: Print as CSV, if not given, the element will be dump to file a raw format (JavatoString()-Method)
Example
JOIN
Description
Parameter
Example
joined = join({predicate = RelationalPredicate('auction_id = auction')}, renamed, nexmarkBid)
LEFTJOIN
Description
Parameter
Example
MAP
Description
Parameter
Example
mapped = map({expressions = ['auction_id * 5','sqrt(auction_id)']}, renamed)
SASE
Description
Dieser Operator ermöglicht es, Anfragen mit zeitlichen Mustern zu definieren. Zu diesem Zweck wird die SASE+ Anfragesprache verwendet und die Anfrage im Parameter query übergeben. Die angebenen Quellen müssen den passenden Typ ![]() haben (für das folgende Beispiel also s05 und s08), die Reihenfolge ist egal. Ggf. muss der Typ einer Quelle vorher noch mit Hilfe der Rename-Operation definiert werden. Der Parameter heartbeatrate legt fest, wie oft ein Hearbeat generiert werden soll, wenn ein Element verarbeitet wurde, welches aber nicht zu einem Ergebnis geführt hat.
haben (für das folgende Beispiel also s05 und s08), die Reihenfolge ist egal. Ggf. muss der Typ einer Quelle vorher noch mit Hilfe der Rename-Operation definiert werden. Der Parameter heartbeatrate legt fest, wie oft ein Hearbeat generiert werden soll, wenn ein Element verarbeitet wurde, welches aber nicht zu einem Ergebnis geführt hat.
Parameter
heartbeatratequeryOneMatchPerInstance
Example
s05 = RENAME({type='s05', aliases = ['ts', 'edge']},...)
PATTERNDETECT({heartbeatrate=1,query='PATTERN SEQ(s05 s1, s08 s2) where skip_till_any_match(s1,s2){ s1.edge=s2.edge } return s1.ts,s2.ts'}, s05, s08)
PROJECT
Description
Parameter
Example
projected = project({attributes = ['auction', 'bidder']}, selected)
PUNCTUATION
Description
Der Punctuation Operator erlaubt das Einfügen von Punctuation in den Verarbeitungsstrom um so nachfolgende Operatoren vor einem möglichen Buffer-Overflow zu schützen. Hierfür hat der Operator zwei Eingänge I1 und I2. Der Eingang I1 stellt den Dateneingang dar und leitet eingehende Tupel direkt an den Ausgang. Der zweite Eingang I2 dient als Frequenzgeber. Sobald die Differenz der Eingangstupel zwischen dem ersten Eingang I1 und dem zweiten Eingang I2 über einen bestimmten Schwellwert steigt, wird in den linken Strom an I1 eine Punctuation eingefügt und ältere Tupel die eventuell danach eintreffen verworfen.
Der Punctuation Operator kann dabei ein nicht deterministisches Verhalten erzeugen, weil das Einfügen von Punctuations von der aktuellen Systemlast abhängen kann und sollte nur verwendet werden, wenn eine normale Verarbeitung der Daten aufgrund ihrer schwankenden Frequenzen nicht möglich ist.
Parameter
Example
punctuation({ratio = 10}, left, right)
RENAME
Description
Renames the attributes.
Parameter
aliases: The list new attribute names to use from now on. If the flagpairsis set,aliaseswill be interpretet as pairs of (old_name, new_name). See the examples below.- type:
pairs:Optional boolean value that flags, if the given list of aliases should be interpretet as pairs of (old_name, new_name). Default value is false.
Example
renamed = rename({aliases = ['auction_id', 'bidder_id', 'another_id']}, projected)(Renames the first attribute to auction_id, the second to bidder_id and the last to another_id.)
renamedPairs = rename({aliases = ['auction_id', 'auction', 'bidder_id', 'bidder'], pairs = 'true'}, projected)(Due the set flag pairs, the rename operator renames the attribute auction_id to auction and bidder_id to bidder.)
ROUTE
Description
This operator can be used to route the elements in the stream to different further processing operators, depending on the predicate.
Parameter
Example
route({predicates=[RelationalPredicate('price > 200'), RelationalPredicate('price > 300')], RelationalPredicate('price > 400')}, nexmark:bid2)
SELECT
Description
Parameter
Example
selected = select({ predicate=RelationalPredicate('price > 100') }, nexmarkBid)
SINK
Description
Parameter
Example
SOCKETSINK
Description
Parameter
Example
STORE
Description
Parameter
Example
TIMESTAMPTOPAYLOAD
Description
Parameter
Example
UNION
Description
Parameter
Example
united = union(mapped, projected)
UNNEST
Description
Parameter
Example
UDO
Description
Parameter
Example
WINDOW
Description
Parameter
Example
//sliding time window windowed = window({size = 5, advance = 1, type = 'time'}, selected) //sliding tuple window partioniert ueber bidder window({size = 5, advance = 1, type = 'tuple', partition=['bidder']}, selected) //unbounded window window({type = 'unbounded'}, selected) //now window (size = 1, advance = 1) window({type = 'time'}, selected) //sliding delta window, reduces time granularity to value of slide window({size = 5, type = 'time', slide = 5}, selected) // Predicate window window({startCondition=RelationalPredicate('a>10'), endCondition = RelationalPredicate('a<10')}, selected)
Benchmark
BATCHPRODUCER
Description
Parameter
Example
BENCHMARK
Description
Parameter
Example
PRIOIDJOIN
Description
Parameter
Example
TESTPRODUCER
Description
Parameter
Example
Data Mining
CLASSIFY
Description
Parameter
Example
HOEFFDINGTREE
Description
Parameter
Example
LEADER
Description
Parameter
Example
SIMPLESINGLEPASSKMEANS
Description
Parameter
Example
FREQUENT_ITEM
Description
Parameter
Example
Storing
DATABASESOURCE
Description
Parameter
Example
DATABASESINK
Description
Parameter
Example
Extension of PQL – Make New Logical Operators Available
This section describes how your new created operators get available in PQL. There are at least two possibilities. The simplest way is to annotate the logical operator, so that Odysseus builds automatically all necessary things. Since this is suitable and useful for most but not in all cases, there is an alternative by implementing an operator builder. Finally, if new parameters are needed, the last section shows how to introduce new types of parameters.
Extension through Annotations of Logical Operators
The annotation framework exists of two parts. First, the operator must be annotated with @LogicalOperator. Secondly, the parameters of the operator must be defined via a @Parameter annotation. These parts are described in the following.
Announce Operators – The @LogicalOperator Annotation
A PQL annotation allows an operator to be automatically loaded for PQL. For that, the logical operator (normally your developed class that inherits AbstractLogicalOperator or implements the interface ILogicalOperator and ends with "AO") is used. It is necessary that this operator is in a package that contains the term logicaloperator in the package name, for example:

The next step is the annotation of the class. The annotation is called "LogicalOperator" and has three parameters:
minInputPorts This is the minimal number of ports that the operator needs.
maxInputPorts This is the maximal number of ports that the operator is can handle
name It describes the (case insensitive) name of the operator.
For the selection you can see in the example, that the selection needs at least one input and is only able to handle one input.

Furthermore, the name is "SELECT". Just this declaration (and the part of the package name) provides all necessary things, so that the operator is loaded and is available in PQL. Thus, you can use it as follows:
SELECT(inputoperator)
As it is described in the previous section, there could be more than one input operator. This number directly depends on the values of maxInputPorts and minInputPorts. Since the example asks for exactly one input operator ((maxInputPorts – minInputPorts)+1 = 1), the query-command SELECT(inputoperator)has also exactly one input operator. So, if you have other values for maxInputPorts and minInputPorts, for example, minimal 0 and maximal 2, there are the following possibilities in PQL:
SELECT()SELECT(inputoperator1)SELECT(inputoperator1, inputoperator2)
Announce Parameters – The @Parameter Annotation
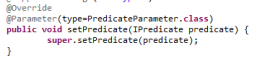
It is also possible to define parameters for the operator. If the operator is annotated with @LogicalOperator, you can define parameters that are also available through PQL. For that, you can use the @Parameter annotation. This annotation is put above a method:
![]()
The method itself should be a setter-method, so that it should be normally void and has exactly one parameter (e.g. int rate in the example). The annotation has seven possible values where only one is necessary, the type:
typeThe type is necessary and describes the kind of the parameter you want to provide. The type is provided via a class that implements IParameter (or AbstractParameter in most cases). For example, the class IntegerParameter asks for an integer. As you may see, the class IntegerParameter is defined as follows:
![]()
The generic type of AbstractParameter (in this case Integer) describes the Java class that the Parameter provides. Therefore, the parameter IntegerParameter is responsible for translating a user defined value (in PQL) into a Java-based class. This class is exactly the same type of the setter (in our example int rate). Remember in this example, that Java provides auto boxing between classes and primitive data types and converts an Integer object automatically to int. Summing up, this means, that the following data types have to be equal (or at least convertible):

Thus, you have to choose an appropriate IParameter based class for your setter. There are already some existing types. Besides some for basic data types like BooleanParameter for a Boolean or DoubleParameter for a double, there are also some special that are described in the following:
PredicateParameter tries to parse a predicate that is normally defined like param = RelationalPredicte('1 < x') for a relational predicate. It uses a predicate builder to build the predicate of type IPredicate before the predicate is passed to the setter, which therefore needs the data type IPredicate. The RelationalPredicate, for example, is built by the Relational-PredicateBuilder that is additionally installed into the OperatorBuilderFactory. Thus, if you have other predicates than Relational-Predicate, you have to create your own IPredicateBuilder, which has to be registered to the OperatorBuilderFactory.
SDFExpressionParameter needs a string as input which is passed to the math expression parser (MEP). MEP converts the string into a SDFExpression that reflects a mathematical expression like (x*3)+y/5 or similar. Thus, the data type of the setter should be SDFExpression.
CreateSDFAttributeParameter creates a SDFAttribute. It takes a two valued list of strings where one value is the name of the attribute and the other value is the data type. For example, the value param=['example', 'integer'] in PQL would be interpreted by CreateSDFAttributeParamater to create a new SDFAttribute with name example and the data type integer. This is normally used by source operators where new SDFAttributes are declared. Since this method delivers an SDFAttribute, your setter function of the logical operator must have SDFAttribute as its parameter.
ResolvedSDFAttributeParameter is similar to the previous one but is used to lookup an existing attribute instead of creating a new one. If you have an operator that needs one of the attribute from the input schema this type can look up the attribute. For example, if you have an input schema like (time, value, bid, id) this parameter allows the use to write parameters like param='bid' to choose one attribute from the schema. Like the previous one, it also delivers an SDFAttribute for your setter method.
![]()
ListParameter is more a wrapper than a real parameter. It allows you to ask for a list of IParameters. This is, for example, useful if you want to have subset of schema and want to use more than one ResolvedSDFAttributeParameter. However, you do not have to use ListParameter as type for the annotation. To use this, you have to use the annotation parameter isList.
isList
isList can be set to true, if you want to provide lists. It only wraps each value into a single list. Thus, the data type of the setter must be List. The generic class of the list is equal to the data type that is defined via type (see the previous section). In the following example, the data type is string and the isList option is set to true.
 As you can see, the data type of the setter is List<String>, because StringParameter delivers a string and isList encapsulates all into List. Remember that the user has to define the parameter as a list in PQL (see above in the first part of this document). For the previous example, the following part should be used in PQL:
As you can see, the data type of the setter is List<String>, because StringParameter delivers a string and isList encapsulates all into List. Remember that the user has to define the parameter as a list in PQL (see above in the first part of this document). For the previous example, the following part should be used in PQL:
options=['now', 'batch', 'small']
This would be passed as a List of these three strings. It is also possible to have other IParameter as type to bundle them into a list. For example, to define a subset of a schema, you can use ResolvedSDFAttributeParameter as a list like in this example:
![]()
isMap
This allows the user to define key value pairs for a parameter like a Map (e.g. a HashMap) in Java. Like in isList, the data type of the value is provided via the type declaration. Additionally, there is also a similar construct for the data type of the key. Thus, you have to define the key through the keytype parameter of the annotation. Since all entries are mapped to a Map, the data type of the setter must be a Map and the generics are the data type that is provided by keytype and by type. For example, if you have pairs of SDFAttribute and a String, the data type of the setter is Map<SDFAttribute, String> like in the following example:
![]()
As describes in the first part of the document, this would be allow the user to define a key value pairs like:
default=['hair' = 'false', 'feathers' = 'true']
Remember, that the keytype is ResovledSDFAttributeParamter so that hair and feathers are attributes from the input schemas! Furthermore, it is also possible to use the isList option as well. This would allow you to have also lists as the value part of the pair
![]()
According to the other example, this allows the users the following example in PQL:
nominal=['hair' = ['false', 'true'], 'feathers' = ['true', 'false']]
keytype
This is similar to type and is used if isMap is also used. See isMap for further details. The default is StringParameter.class
name
This value describes the name of the parameter which is used by PQL. Normally the attribute name of the setter/getter is used. If you have the following example
![]()
The attribute name would be AttributeX (the set/get is omitted!). Thus, the name of the parameter would be attributex (case insensitive). Since the name is not appropriate in most cases, the name parameter is used to define a new name. In the example, the parameter is named to X, so that the user has to use X='id' instead of attributex='x' in PQL.
optional
It marks the parameter as optional so that the parameter must not be defined by the user. The default is false, so that each parameter has to be defined by the user unless this option is not set to true.
deprecated
Marks the parameter as deprecated and is used when the parameter is not needed anymore or is replaced by another parameter and is going to be removed in the future. The default value is false.
Extension through Operator Builders
This part shows how to extend PQL with new operators, if annotating is not really possible, for example, if you have to build special parameters or if you have to use the constructor. There are two steps necessary. First you need an operator builder and secondly, you have to register the operator builder via a service.
Create the Operator Builder
This step is the creation of the operator builder. Since most steps have nearly the same semantic like the annotation, this description references some things. The steps for creating an operator builder are as follows:
Create a new class and inherit the AbstractOperatorBuilder.
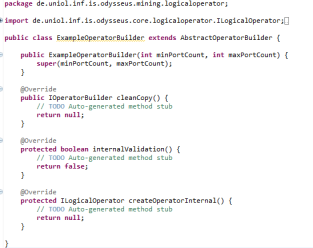
To remove the warning, you can generate a serial version id. Then you have to implement three methods and a constructor, which are described in more detailed in the following.
Constructor
The constructor asks for two integers: minPortCount and maxPortCount. These integers are equal to minInputPorts and maxInputPorts like they are described in the annotation (see previous section). Thus, they indicate the minimum and maximum number of incoming data ports (e.g. a selection has exactly min=max=1 port). Thus, you should pass your numbers in you constructor to the super constructor, for example, super(1, 1) if you have exactly one port. The next step is the definition of parameters. A common way is to declare and initialize each parameter of type IParameter as a class field and finally to announce the parameter by using the addParameter method in the constructor. This is shown in the following for a StringParameter called sourceName.
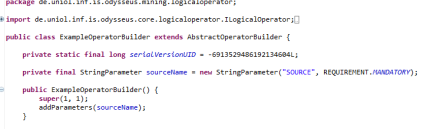
According to the definition of parameters that is described in the annotation-part of this document, each parameter may have several options. Besides the name (see name for annotations), in most cases you also have to set the requirement and the usage. The usage is equal to optional for annotations so that you can define if the user must provide this parameter or not. Usage is similar because it reflects if the parameter is recent or deprecated (see deprecated for annotations). Since the default of usage is recent, the parameter sourceName of the example is a recent parameter that is mandatory (not optional). Of course, the exactly initializations strongly depends on the class that implements IParameter. To define lists (see the isList option for annotations), you have to use the ListParameter. You also have to pass the kind of IParameter that is provided by the class. For example, if you want to provide a list of strings, you have to use ListParameter in combination with StringParameter:

Notice, the type of the generic type of ListParameter must be equal to the type that is returned by the inner parameter (called singleParameter). In the example above, the generic type is String because the defined StringParamter also delivers a String (see type for annotations for further details).
cleanCopy
This method is used to create a new, fully clean instance of the operator builder. Thus, you can simply return a new instance:

internalValidation
This method is invoked during the parsing of a PQL query right before the operators are built. It allows the class, for example, to check whether all necessary things are provided (each mandatory parameter was used by the user) or if the parameters have correct values. The AbstractOperatorBuilder already checks some things. For example, if there are (according to minPortCount) enough input operators and (according to maxPortCount) not too much input operators. It also calls the validate-method for each parameter. Thus, each parameter itself is already validated before internalValidation is called. Therefore, you normally do not have to check, if the parameter is set correctly. Notices, that this parameter based validations are not operator dependent. The ResolvedSDFAttributeParameter, for example, checks in the validate method, if one of the input schemas has the attribute that was defined by the user, but it does not check if—according to the operator—the correct attribute was chosen. The IntegerParameter may only check, if the given value is an integer, but not if it is between 100 and 150.
So, the internalValidation method could be used for validating operator based things or if you need to combine two or more parameters, e.g. if the value of one parameter depends on the value of another parameter. For example, we check if the sourceName exists in the data dictionary:
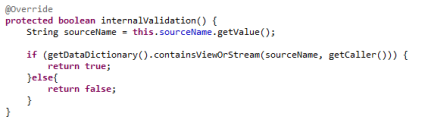
You can also see that you can access the value of the parameter through the method getValue(). Furthermore, each parameter has a method called hasValue()that is used to check if the parameter was used by the user and has a value.
createOperatorInternal
Finally, this method is used to create the operator itself. In our case, we simply use the parameters and create the logical operator.

Register the Operator Builder
The next step is to register the operator builder to the operator builder factory. This is done by a service declaration. First, you have to create a component definition, which is normally in a folder called "OSGI-INF".
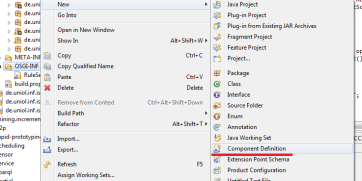
Choose your OperatorBuilder as Class and give an unique name
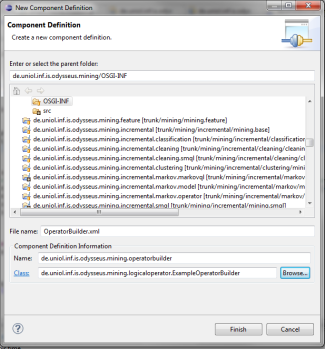
In the next step, you have to add (under the "services" tab) the provided service. Click "Add…" and add your OperatorBuilder so that it look like the following:
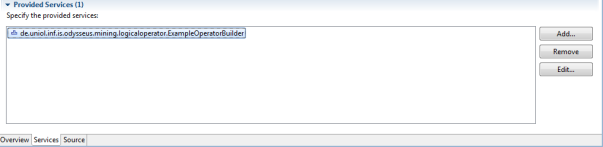
Take care that your bundle is loading so that the operator builder can be registered.
Adding New Parameter Types
Since there are already a lot of parameter types, firstly check if there is already a suitable parameter. However, if you need a new parameter type, you have to implement the interface IParameter. We recommend using the existing abstract implementation AbstractParameter. We show how to create a new parameter type with the help of an example.
In our example we want to have a parameter that resolves a file from a given path. We first create a new class called FileParameter and inherit the AbstractParamter class. The generic type T that is provided by the AbstractParameter is used to declare the java class that is returned by the Parameter. In our case, this should be the class java.io.File.
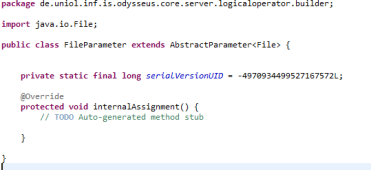
You may also generate a serial version uid and create the method stub for the one needed method called internalAssignment(). This method is responsible for transforming the value that is given by the user into the output format (in our case File). We assume that the user provides a string that holds a path. We can access this value via the inputValue variable, so that we are casting this value to string:
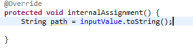
Now, we can create a File object and set this object as the resulting value:

As you can see, the output-value is set via the setValue() method. That's all. Notice, that we assume a String so that the user should use a string-based declaration (using apostrophes) like fileparam='C:/example.csv'.
If you need further functionalities, it is possible to override some methods. For example, if you want to validate the input, you can overwrite internalValidateion(). In our example, we can, for example, check whether the file exists or not:
