...
A special case is the treatment of groups, e.g., if not all elements should be counted, but the elements with a special attribute value (e.g. the count of bids for an auction). In this case, the AGGREGATE operator keeps an own state for each group and provides special handling for out of order events.
Parameter
group_by:An optional list of attributes over which the grouping should occur.aggregations:A list if elements where each element contains up to four string:- The name of the aggregate function, e.g. MAX
- The input attribute over which the aggregation should be done. This can be a single value like
'price'or for some aggregate function a list \['price','id'\]or'*'for all Attributes. The latter one can be used for aggregations where so single attribute is relevant, e.g. with COUNT - The name of the output attribute for this aggregation
- The optional type of the output. If not given, DOUBLE will be used.
dumpAtValueCount:This parameter is used in the interval approach. Here a result is generated, each time an aggregation cannot be changed anymore. This leads to fewer results with a larger validity. With this parameter the production rate can be raised. A value of 1 means, that for every new element the aggregation operator receives new output elements are generated. This leads to more results with a shorter validity.outputPA: This parameter allow to dump partial aggregates instead of evaluted values. The partial aggregates can be send to other aggregation operators and do a final aggregation (e.g. in case of distribution). The input schema of an aggregate operator that read partial aggregates must state a datatype that is a partial aggregated (see example below). Remark: Aggregate has one input and requires ordered input. To combine different parital aggregations e.g. a union operator is needed to reorder the input elements.drainAtDone: Boolean, default true: If done is called, all not already written elements will be written.drainAtClose: Boolean, default false: If close is called, all not already written elements will be written.FastGrouping: Use hash code instead of compare to create group. Potentially unsafe!
New: In the standard case the AGGREGATE operator creates outputs with start and end timestamp. This could lead to higher latency because the operator has to wait for the next element to set the end time stamp. With
latencyOptimized= true
the operator creates for every new incomming element a new output and sets only the start time stamp for the output. If the input contains equals start time stamps, there will be an output for every incomming element, too. See example below.
Aggregation Functions
The set of aggregate functions is extensible. The following list is in the core Odysseus:
...
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
SELECT MAX(price) AS max_price FROM input GROUP BY bidder |
Latency Optimized
The latency optimized version of the operator does not create time intervals for the output but sets only the start time stamp. This has the advantage, that for every state change a new element is created.
Here is an example to see the difference.
Suppose an input as following:
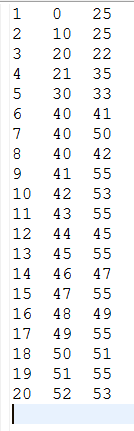
For the non latency optimized (default) case:
| Code Block |
|---|
#PARSER PQL
#IFSRCNDEF overlapping
#RUNQUERY
overlapping := ACCESS({
source='overlapping ',
wrapper='GenericPull',
transport='file',
protocol='simplecsv',
datahandler='tuple',
schema=[
['a1', 'integer'],
['start', 'startTIMESTAMP'],
['end', 'endTIMESTAMP']
],
options=[
['filename', '${PROJECTPATH}/overlappingInput.csv'],
['delimiter', '\t']
]
}
)
#endif
#RUNQUERY
out = AGGREGATE({
aggregations = [['COUNT', '*', 'counter']]
},
overlapping
) |
the output will be as follows:
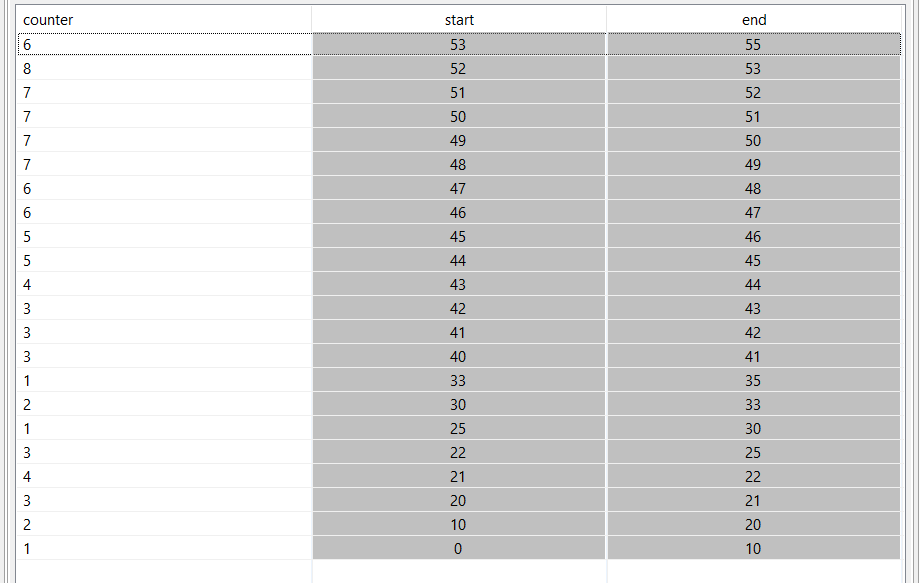
Here you can see start and end time stamps in the output.
For the latency optimized case:
| Code Block |
|---|
#PARSER PQL
#RUNQUERY
out = AGGREGATE({
aggregations = [['COUNT', '*', 'counter']], LatencyOptmized = true
},
overlapping
) |
the output differs:
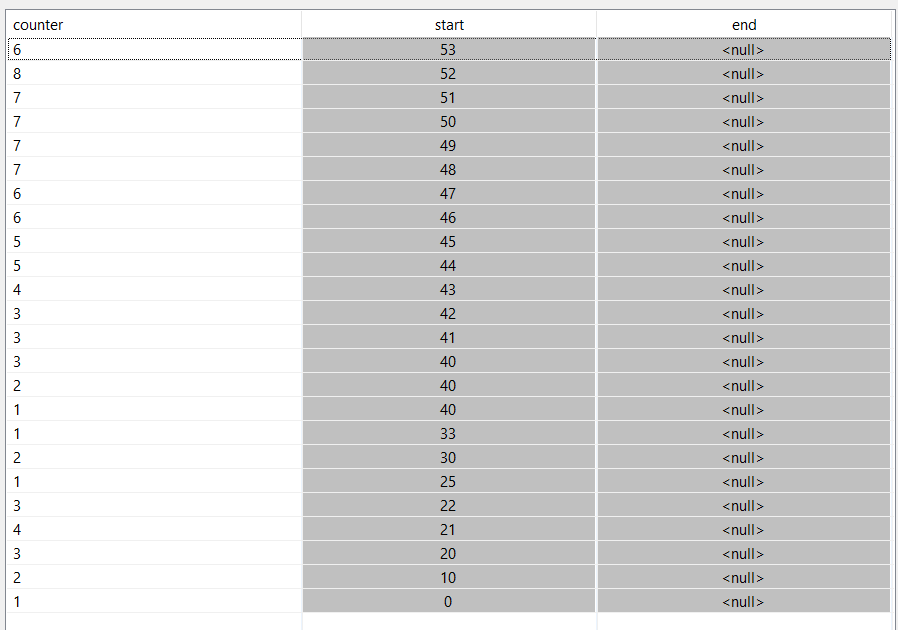
The most obvious thing is: There are no end time stamps.
But there is one more thing different. In the standard case above there is for each start time stamp only one value (see 40), and here for each incoming tuple a value.