The Odysseus Procedural Query Language (PQL) – Usage and Extension
This document describes the basic concepts of the Procedural Query Language (PQL) of Odysseus, shows how to use and extend the language. In contrast to languages SQL based languages like the Continuous Query Language (CQL) or StreamSQL, PQL is more procedural and functional than declarative. The first part of this document is for users and shows how to formulate queries with PQL. The second part of the document is intended for developers who want to extend PQL.
Using PQL in Queries
PQL is an operator based language where an operator can be seen as a logical building block of the query. Thus, PQL is the connection of several operators. Since Odysseus differentiates between logical operators and their physical operators, which are the implementing counterpart, PQL is based upon logical operators. Therefore, it may happen that the query gets changed during the transformation from the logical query plan into the physical query plan. This includes also logical optimization techniques like the restructuring of the logical query plan. To avoid this, you can explicitly turn off the query optimization.
...
An operator can be used in PQL via its name and some optional settings, which can be compared with a function and the variables for the function:
OPERATORNAME(parameter, operator, operator, ...)
The first variable (parameter) describes operator dependent parameters and is used for configuring the operator. Note, that there is only one parameter variable! The other variables (operator) are input operators, which are the preceding operators that push their data into this operator. The inputs of an operator can be directly defined by the definition of another operator:
OPERATOR1(parameter1, OPERATOR2(Parameter2, OPERATOR3(...)))
Except for source operators (usually the first operator of a query) each operator should have at least one input operator. Thus, the operator can only have parameters:
OPERATOR1(parameter1)
Accordingly, the operator may only have input operators but no parameters:
OPERATOR1(OPERATOR2(OPERATOR3(...)))
Alternatively, if the operator has neither parameters nor input operators, the operator only exists of its name (without any brackets!), so just:
OPERATORNAME
It is also possible to combine all kinds of definitions, for example:
OPERATOR1(OPERATOR2(Parameter2, OPERATOR3))
Intermediate Names, Views and Sources
Since the nesting of operators may lead to an unreadable code, it is possible to name operators to reuse intermediate result. This is done via the "=" symbol. Thus, we can temporary save parts of the query, for example:
Result2 = OPERATOR2(Parameter2, OPERATOR3)
The defined names can be used like operators, so that we can insert them as the input for another operator, for example:
Result2 = OPERATOR2(Parameter2, OPERATOR3)OPERATOR1(Result2)
There could be also more than one intermediate result, if they have different names:
Result1 = OPERATOR1(Parameter1, …)Result2 = OPERATOR2(Parameter2, Result1)Result3 = OPERATOR3(Parameter3, Result2)
And you can use the intermediate name more than one time, e.g. if there are two or more operators that should get the same preceding operator:
Result1 = OPERATOR1(Parameter1, …)OPERATOR2(Parameter2, Result1)OPERATOR3(Parameter3, Result1)
All intermediate results that are defined via the "=" are only valid within the query. Thus, they are lost after the query is parsed and runs. This can be avoided with views.
A view is defined like the previous described intermediate results but uses ":=" instead of "=", e.g.:
Result2 := OPERATOR2(Parameter2, OPERATOR3)
Such a definition creates an entry into the data dictionary, so that the view is globally accessible and can be also used in other query languages like CQL.
Alternatively, the result of an operator can also be stored as a source into the data dictionary by using "::="
Result2 ::= OPERATOR2(Parameter2, OPERATOR3)
The difference between a view and a source is the kind of query plan that is saved into the data dictionary and is reused. If a view is defined, the result of the operator is saved as a logical query plan, which exists of logical operators. Thus, if another query uses the view, the logical operators are fetched from the data dictionary and build the lower part of the new operator plan or query. If an operator is saved as a source, the result of the operator is saved as a physical query plan, which exists of already transformed and maybe optimized physical operators. Thus, reusing a source is like a manually query sharing where parts of two or more different queries are used together. Additionally, the part of the source is not recognized if the new part of the query that uses the source is optimized. In contrast, the logical query plan that is used via the a view is recognized, but will not compulsorily lead to a query sharing.
Finally, all possibilities gives the following structure:
QUERY = (TEMPORARYSTREAM | VIEW | SHAREDSTREAM)+
TEMPORARYSTREAM = STROM "=" OPERATOR
VIEW = VIEWNAME ":=" OPERATOR
SHAREDSTREAM = SOURCENAME "::=" OPERATOR
Parameters – Configure an Operator
...
- FIRST: The first element
- LAST: The last element
- NTH: The nth element
- RATE:??
BUFFER
Description
Typically, Odysseus provides a buffer placement strategy to place buffers in the query plan. This operator allows adding additional buffers by hand.
...
- Type: The type of the buffer. The following types are currently part of Odysseus:
- Normal: This is the standard type and will be used if the type parameter is absent
- Currently, no further types are supported in the core Odysseus. In the future, there will be some buffers integrated to treat prioritized elements.
- MaxBufferSize: If this value is set, a buffer will block if it reaches its maximal capacity. No values will be thrown away; this is not a load shedding operator!
Example
BUFFEREDFILTER
Description
...
BufferedFilter({predicate = RelationalPredicate('id == 2 || id == 4 || id == 10'), bufferTime = 5000, deliverTime = 20000}, nexmark:bid2, nexmark:person2)
CALCLATENCY
Description
Odysseus has some features to measure the latency of single stream elements. This latency information is modeled as an interval. An operator in Odysseus can modify the start point of this interval. This operator sets the endpoint and determines the place in the query plan, where the latency measurement finds place. The can be multiple operators in the plan, to measure latency at different places.
Parameter
Example
CHANGEDETECT
Description
This operator can be used to filter out equal elements and reduce data rate.
...
Description
Parameter
Example
EXISTENCE
Description
This operator tests an existence predicate and can be used with the type EXISTS (semi join) and NOT_EXISTS (anti semi join). The predicates can be evaluated against the element from the first input and the second input.
Semi join: All elements in the first input for which there are elements in the second input that fulfills the predicate are sent.
Semi anti join: All elements in the first input for which there is no element in the second input that fulfills the predicate are sent.
...
existencial = existence({type='EXISTS', predicate=RelationalPredicate('auction = auction_id')}, projected, renamed)
existence({type='NOT_EXISTS', predicate=RelationalPredicate('auction = auction_id')}, projected, renamed)
FILESINK
Description
The operator can be used to dump the results of an operator to a file.
...
Description
Parameter
Example
MAP
Description
Parameter
Example
...
s05 = RENAME({type='s05', aliases = ['ts', 'edge']},...)
PATTERNDETECT({heartbeatrate=1,query='
PATTERN SEQ(s05 s1, s08 s2)
where skip_till_any_match(s1,s2){
s1.edge=s2.edge}
return s1.ts,s2.ts'}
, s05, s08)
PROJECT
Description
Parameter
...
projected = project({attributes = ['auction', 'bidder']}, selected)
PUNCTUATION
Description
Der Punctuation Operator erlaubt das Einfügen von Punctuation in den Verarbeitungsstrom um so nachfolgende Operatoren vor einem möglichen Buffer-Overflow zu schützen. Hierfür hat der Operator zwei Eingänge I1 und I2. Der Eingang I1 stellt den Dateneingang dar und leitet eingehende Tupel direkt an den Ausgang. Der zweite Eingang I2 dient als Frequenzgeber. Sobald die Differenz der Eingangstupel zwischen dem ersten Eingang I1 und dem zweiten Eingang I2 über einen bestimmten Schwellwert steigt, wird in den linken Strom an I1 eine Punctuation eingefügt und ältere Tupel die eventuell danach eintreffen verworfen.
Der Punctuation Operator kann dabei ein nicht deterministisches Verhalten erzeugen, weil das Einfügen von Punctuations von der aktuellen Systemlast abhängen kann und sollte nur verwendet werden, wenn eine normale Verarbeitung der Daten aufgrund ihrer schwankenden Frequenzen nicht möglich ist.
...
punctuation({ratio = 10}, left, right)
RENAME
Description
Parameter
...
renamed = rename({aliases = ['auction_id', 'bidder_id']}, projected)
ROUTE
Description
This operator can be used to route the elements in the stream to different further processing operators, depending on the predicate.
...
selected = select({ predicate=
| Anchor | ||||
|---|---|---|---|---|
|
SINK
Description
Parameter
Example
SOCKETSINK
Description
Parameter
...
Description
Parameter
Example
TIMESTAMPTOPAYLOAD
Description
Parameter
Example
UNION
Description
Parameter
...
Description
Parameter
Example
UDO
Description
Parameter
Example
WINDOW
Description
Parameter
...
//sliding time window
windowed = window({size = 5, advance = 1, type = 'time'}, selected)
//sliding tuple window partioniert ueber bidder
window({size = 5, advance = 1, type = 'tuple', partition=['bidder']}, selected)
//unbounded window
window({type = 'unbounded'}, selected)
//now window (size = 1, advance = 1)
window({type = 'time'}, selected)
//sliding delta window, reduces time granularity to value of slide
window({size = 5, type = 'time', slide = 5}, selected)
// Predicate window
window({startCondition=RelationalPredicate('a>10'), endCondition = RelationalPredicate('a<10')}, selected)
Benchmark
BATCHPRODUCER
Description
Parameter
Example
BENCHMARK
Description
Parameter
Example
PRIOIDJOIN
Description
Parameter
Example
TESTPRODUCER
Description
Parameter
Example
Data Mining
CLASSIFY
Description
Parameter
Example
HOEFFDINGTREE
Description
Parameter
Example
LEADER
Description
Parameter
Example
SIMPLESINGLEPASSKMEANS
Description
Parameter
Example
FREQUENT_ITEM
Description
Parameter
Example
Storing
DATABASESOURCE
Description
Parameter
Example
DATABASESINK
Description
Parameter
Example
Extension of PQL – Make New Logical Operators Available
...
isList can be set to true, if you want to provide lists. It only wraps each value into a single list. Thus, the data type of the setter must be List. The generic class of the list is equal to the data type that is defined via type (see the previous section). In the following example, the data type is string and the isList option is set to true.
 As you can see, the data type of the setter is List<String>, because StringParameter delivers a string and isList encapsulates all into List. Remember that the user has to define the parameter as a list in PQL (see above in the first part of this document). For the previous example, the following part should be used in PQL:
As you can see, the data type of the setter is List<String>, because StringParameter delivers a string and isList encapsulates all into List. Remember that the user has to define the parameter as a list in PQL (see above in the first part of this document). For the previous example, the following part should be used in PQL:
options=['now', 'batch', 'small']
This would be passed as a List of these three strings. It is also possible to have other IParameter as type to bundle them into a list. For example, to define a subset of a schema, you can use ResolvedSDFAttributeParameter as a list like in this example:
![]()
isMap
This allows the user to define key value pairs for a parameter like a Map (e.g. a HashMap) in Java. Like in isList, the data type of the value is provided via the type declaration. Additionally, there is also a similar construct for the data type of the key. Thus, you have to define the key through the keytype parameter of the annotation. Since all entries are mapped to a Map, the data type of the setter must be a Map and the generics are the data type that is provided by keytype and by type. For example, if you have pairs of SDFAttribute and a String, the data type of the setter is Map<SDFAttribute, String> like in the following example:
![]()
As describes in the first part of the document, this would be allow the user to define a key value pairs like:
default=['hair' = 'false', 'feathers' = 'true']
Remember, that the keytype is ResovledSDFAttributeParamter so that hair and feathers are attributes from the input schemas! Furthermore, it is also possible to use the isList option as well. This would allow you to have also lists as the value part of the pair
![]()
According to the other example, this allows the users the following example in PQL:
nominal=['hair' = ['false', 'true'], 'feathers' = ['true', 'false']]
...
This method is used to create a new, fully clean instance of the operator builder. Thus, you can simply return a new instance:

internalValidation
This method is invoked during the parsing of a PQL query right before the operators are built. It allows the class, for example, to check whether all necessary things are provided (each mandatory parameter was used by the user) or if the parameters have correct values. The AbstractOperatorBuilder already checks some things. For example, if there are (according to minPortCount) enough input operators and (according to maxPortCount) not too much input operators. It also calls the validate-method for each parameter. Thus, each parameter itself is already validated before internalValidation is called. Therefore, you normally do not have to check, if the parameter is set correctly. Notices, that this parameter based validations are not operator dependent. The ResolvedSDFAttributeParameter, for example, checks in the validate method, if one of the input schemas has the attribute that was defined by the user, but it does not check if—according to the operator—the correct attribute was chosen. The IntegerParameter may only check, if the given value is an integer, but not if it is between 100 and 150.
So, the internalValidation method could be used for validating operator based things or if you need to combine two or more parameters, e.g. if the value of one parameter depends on the value of another parameter. For example, we check if the sourceName exists in the data dictionary:
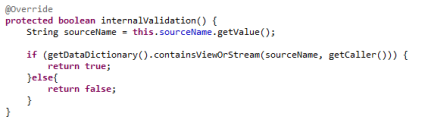
You can also see that you can access the value of the parameter through the method getValue(). Furthermore, each parameter has a method called hasValue()that is used to check if the parameter was used by the user and has a value.
...
Finally, this method is used to create the operator itself. In our case, we simply use the parameters and create the logical operator.

Register the Operator Builder
The next step is to register the operator builder to the operator builder factory. This is done by a service declaration. First, you have to create a component definition, which is normally in a folder called "OSGI-INF".
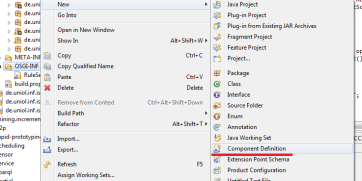
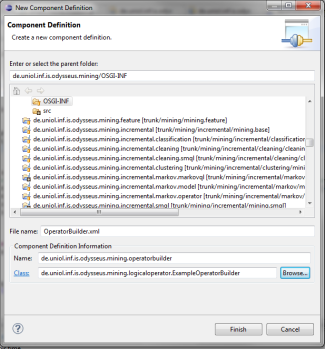
Choose your OperatorBuilder as Class and give an unique name
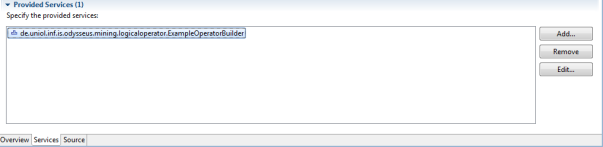
In the next step, you have to add (under the "services" tab) the provided service. Click "Add…" and add your OperatorBuilder so that it look like the following:
Take care that your bundle is loading so that the operator builder can be registered.
Adding New Parameter Types
...