...
Suppose an input as following:
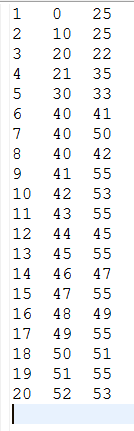
For the non latency optimized (default) case:
| Code Block |
|---|
#PARSER PQL
#IFSRCNDEF overlapping
#RUNQUERY
overlapping := ACCESS({
source='overlapping ',
wrapper='GenericPull',
transport='file',
protocol='simplecsv',
datahandler='tuple',
schema=[
['a1', 'integer'],
['start', 'startTIMESTAMP'],
['end', 'endTIMESTAMP']
],
options=[
['filename', '${PROJECTPATH}/overlappingInput.csv'],
['delimiter', '\t']
]
}
)
#endif
#RUNQUERY
out = AGGREGATE({
aggregations = [['COUNT', '*', 'counter']]
},
overlapping
) |
the output will be as follows:
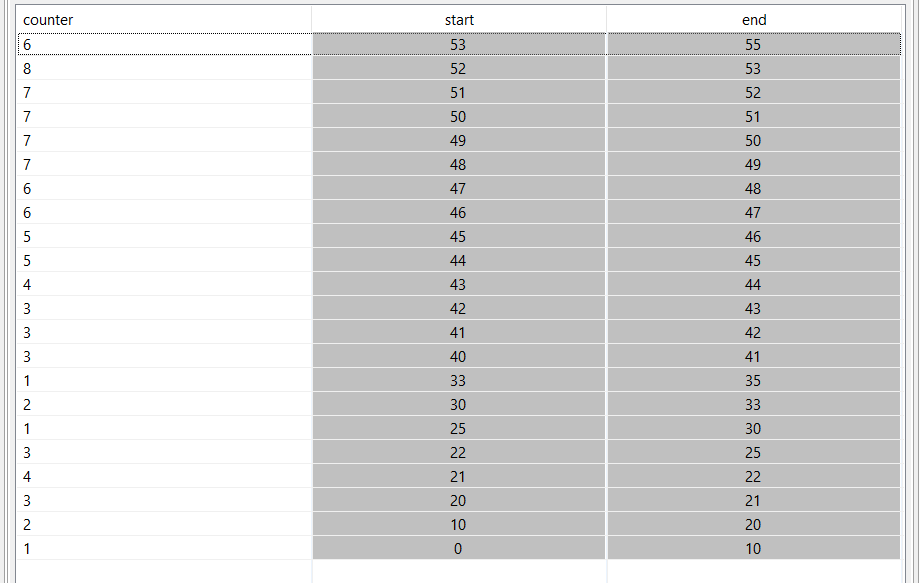
Here you can see start and end time stamps in the output.
For the latency optimized case:
| Code Block |
|---|
#PARSER PQL
#RUNQUERY
out = AGGREGATE({
aggregations = [['COUNT', '*', 'counter']], LatencyOptmized = true
},
overlapping
) |
the output differs:
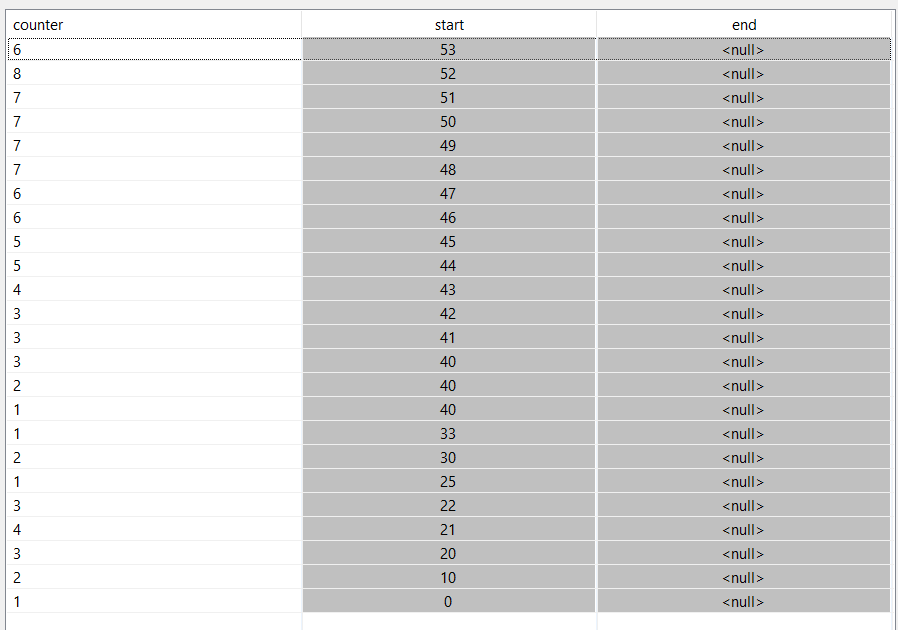
The most obvious thing is: There are no end time stamps.
But there is one more thing different. In the standard case above there is for each start time stamp only one value (see 40), and here for each incoming tuple a value.