Your will need to install the classification feature for this. See https://git.swl.informatik.uni-oldenburg.de/projects/OI/repos/classification/browse for further information and a german thesis for further information.
Beneath the already existing Machine Learning Feature, we provide a new (experimental) feature, that focuses on classfication and utilizes the Aggregation operator for this. To use this feature, you need to install the Classification Feature.
Learner
This operator creates classifiers as output. These classifiers can be used in the classify operator to classify elements.
NonIncrementalClassificationLearner
classifier = CLASSIFICATION_LEARNER(
{LABELATTRIBUTE = 'label',
ALGORITHM = 'WekaGeneric',
SUBALGORITHM = 'J48',
CLASSIFIEROPTIONS = '-U'}, windowed)
Remark: Internally, this will be translated to. See Explanations of parameters there (LABELATTRIBUTE = LABEL_ATTRIBUTE, SUBALGORITHM=WEKA_ALGORITHM, CLASSIFIEROPTIONS=WEKA_OPTIONS)
classifier = AGGREGATION({
aggregations = [
['FUNCTION' = 'NonIncrementalClassificationLearner',
'LABEL_ATTRIBUTE' = 'label',
'ALGORITHM' = 'WekaGeneric',
'WEKA_ALGORITHM' = 'J48',
'WEKA_OPTIONS' = '-U']
],
eval_at_new_element = false,
eval_before_remove_outdating = true
},
windowed
)
This first version, the NonIncrementalClassificationLearner, is a wrapper for WEKA classifier (current supported version is 3.8) learners and needs the following parameters
- LABEL_ATTRIBUTE: In the input data, which is the attribute with the label, that should be learned
- WEKA_ALGORITHM: Which WEKA Algorithm should be used. At the moment, the following algorithms are available. See WEKA for more information:
- BayesNet
- NaiveBayes
- NaiveBayesMultinomial
- NaiveBayesUpdateable
- GaussianProcesses
- Logistic
- MultilayerPerceptron
- SimpleLogistic
- SMO
- IBk
- KStar
- LWL
- DecisionTable
- JRip
- OneR
- PART
- DecisionStump
- HoeffdingTree
- J48
- LMT
- RandomForest
- RandomTree
- REPTree
- WEKA_OPTIONS: The options that should be given for the algorithm (see https://weka.sourceforge.io/doc.stable/weka/classifiers/Classifier.html for information about the given parameters)
- GROUP_BY (Optional): Grouping Attributes that should be used.
- ATTRIBUTES (Optional): Attributes that should be used for building the classifier. If not given, the input schema will be used. If not given and group_by is given, the attributes are the input attributes without the group_by attributes.
Important: EVAL_AT_NEW_ELEMENT = false, EVAL_BEFORE_REMOVE_OUTDATING = true must be provided this way. Currently, there is no check, for this and output may be wrong.
It is now (2024-03-08) possible to use grouping for the aggregation version. In this case, for each Group the will be trained an individuell classifier IN THIS CASE YOU WILL NEED TO USE INPUT_ATTRIBUTES as option to define the attributes that should be used for training (without the grouping attributes). If you use this, then the classifier must use the same attribute for grouping!
IncrementalClassificationLearner
classifier = AGGREGATION({AGGREGATIONS = [
['FUNCTION' = 'IncrementalClassificationLearner',
'LABEL_ATTRIBUTE' = 'label', 'ALGORITHM' = 'HATT',
'BATCH_SIZE' = '100', 'CONFIDENCE' = '0.01']
]}, trainingdata)
This is an inkremental learner ('FUNCTION' = 'IncrementalClassificationLearner'). ATM only Hoeffding Anytime Tree (HATT) is supported ('ALGORITHM' = 'HATT'). The operator needs the following parameters:
- BATCH_SIZE: With this factor is it possible to define the number of elements that should be processed, before a new classifier is created.
- CONFIDENCE: This is a HATT-specific parameter for the attribute selection
Classify
This operator has two inputs:
- The first input is the source with the data, that should be classified (remark, this must be the same content as the Learner, without the label of course)
- The second input is the classifier to use. This can be retrieved from a learner operator or read from outside.
The operator can be used with the following parameters:
- ATTRIBUTES: A list of input attributes from the data that should be used for classification. If not given, any input attribute will be used. This is helpful if attributes should be kept in the output that are not part of the classification, e.g. in a fuel price scenario the id of the fuel station.
- returnDistribution (boolean): If the classifier can return a distribution, this flag can be set to retrieve the distribution instead of the classification value
- returnNumber/returnValue (boolean): E.g. in case of a regression, there are not labels. In this case, this flag tells Odysseus not to do a mapping to the classification labels.
- pathModel: when reading serialized weka models (see below)
- group_by: A list of attributes. If set: The classification is done for each different group based on this attributes.
- CLASSIFIERATTRIBUTE: When reading the classifier from another input, this is the name of the attribute that contains the classifier.
- isWekaModel: set to true, if read from weka and needs special handling
- labels: A list of Strings. When using a store classifier from weka that should output labels, this list is used for the labeling.
classified = CLASSIFICATION(testdata, classifier)
Reading and Writing Classifier
As it is not always feasible to create a new classifier for each new query, Odysseus provides an experimental approach to store and load classifiers. To avoid problems with not printable characters, use the MAP operator and convert the classifier to base64. This classifier can be written to a database or as in the following into a csv file:
map = MAP({EXPRESSIONS = [['base64encode(classifier)','encoded']]}, classifier)
out = CSVFILESINK({SINK = 'output', WRITEMETADATA = false, FILENAME = '${PROJECTPATH}/out/classifierOut.csv'}, map)
Reading of classifiers can be done as in the following and feed into a classification operator.
#PARSER PQL
#ADDQUERY
classIn = CSVFILESOURCE({SCHEMA = [['classifierBASE64', 'String']], FILENAME = '${PROJECTPATH}/out/classifierOut.csv', SOURCE = 'classifierSource'})
classifier = MAP({EXPRESSIONS = [['base64decode(classifierBASE64)','classifier']]}, classIn)
classified = CLASSIFICATION(testdata, classifier)
Remark: This work is experimental. Please provide an Bug Report (How to report a bug) if you find any problems.
Weka Classifier
It is also possible to use trained weka classifiers, that are not stored with Odysseus.
Remark: Experimental: This is no longer necessary. You can use any Weka-Classifier. In this case you will need to add Labels and, if not all input should be part of the classification, attributes.
In this case you can use a FilteredClassifier as meta classifier. In options add the wanted classifier. If data are based on strings, add StringToNominalFilter else add NumericToNominalFilter as option. Learn model and store. See following activity diagram (in german).
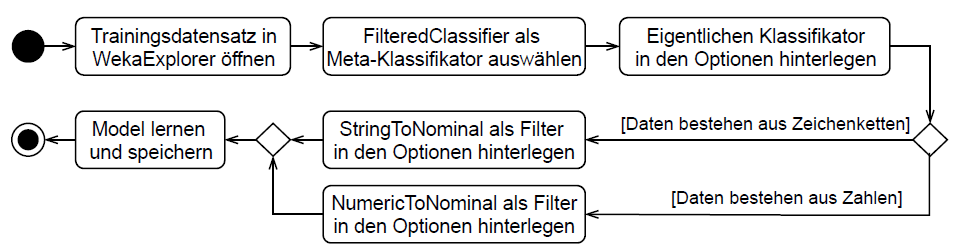
TODO: Translate
Weka beinhaltet Filter die dem Lernprozess vorausgehen können. Diese können unter anderem Attribute mit Zeichenketten oder numerischen Werten in Attribute mit nominalen Werten umwandeln. Der implementierte WekaClassifierWrapper unterstützt nur nominale Attribute, daher muss beim Lernen des Klassifikators in Weka in jedem Fall ein entsprechender Filter vorausgehen. Die Zuordnung der Zeichenketten, beziehungsweise Zahlen zu den nominalen Werten wird dabei auch im WekaClassifierWrapper benötigt und seinem Konstruktor übergeben. Damit Weka diese Zuordnung beim Speichern eines Modells anhängt, muss der Filter über einen speziellen Meta-Klassifikator FilteredClassifier vorgeschaltet werden. Nachdem der Klassifikator konfiguriert und gelernt wurde, kann er gespeichert werden und beinhaltet die erforderliche Zuordnung.
In this case, you can load the classifier from a file:
classified = CLASSIFICATION({
PATHTOMODEL = '${PROJECTPATH}\wekamodel.model'
},
toClassify
)
Original Weka Classifier
This operator has the following optional parameter:
isWekaModel: This factor makes it possible to use a model trained in Weka (outside of Odysseus) as input on port 1. The following example shows a use case, where the Weka model is first loaded from a database and then used in the CLASSIFICATION operator:
Remark: A least the model_content attribute needs to be read from the database. The other attributes are optional now.
timer = TIMER({PERIOD = 1000000000, SOURCE = 'testdata'})
wekaModel = dbenrich({connection='connection3', query='SELECT id, model_name, labels, model_content, output_attributes FROM trained_models where id=5', multiTupleOutput='false', attributes=[]}, timer)
classified = CLASSIFICATION({isWekaModel='true'}, testdata, wekaModel)