-
Created by
 user-12fa0, last updated on Jun 23, 2017
4 minute read
user-12fa0, last updated on Jun 23, 2017
4 minute read
In the Interactive PMCube Explorer, there are two different ways to model the case and event attributes.
Dimension: A dimension represents an axis of the data cube that can be used to partition the event data into sublogs. Each dimension consist of a set of pair-wise distinct values. Furthermore, Interactive PMCube Explorer allows the user to define dimension hierarchies in a tree-like structure. Dimensions should be the preferred way of modeling the attributes. However, they may not be appropriate in case of many rare attribute values as this can result in sparse data cubes and missing representativeness of of the process models. To avoid such problems, sets of different attribute values may be grouped into artificial categories, e.g. representing intervals of values. If this is not meaningful, the attributes can also be stored as simple attributes.
Simple attribute: This way of modeling directly attaches an attribute to its case or event. In contrast to dimensions, simple attributes are very limited in their usage (e.g., they cannot be used for roll-up and drill-down). Therefore, it is only recommended to use simple attributes for avoiding the loss of data if the attribute cannot be meaningfully mapped to a dimension.
The database schema manages case and event attributes on different levels. This is not only reflected in the definition of OLAP operations, but also by the database schema that stores cases and events in different tables. The following figure shows the generic database schema of the data warehouse which is an extension of the traditional snowflake schema commonly used for relational data warehouses.
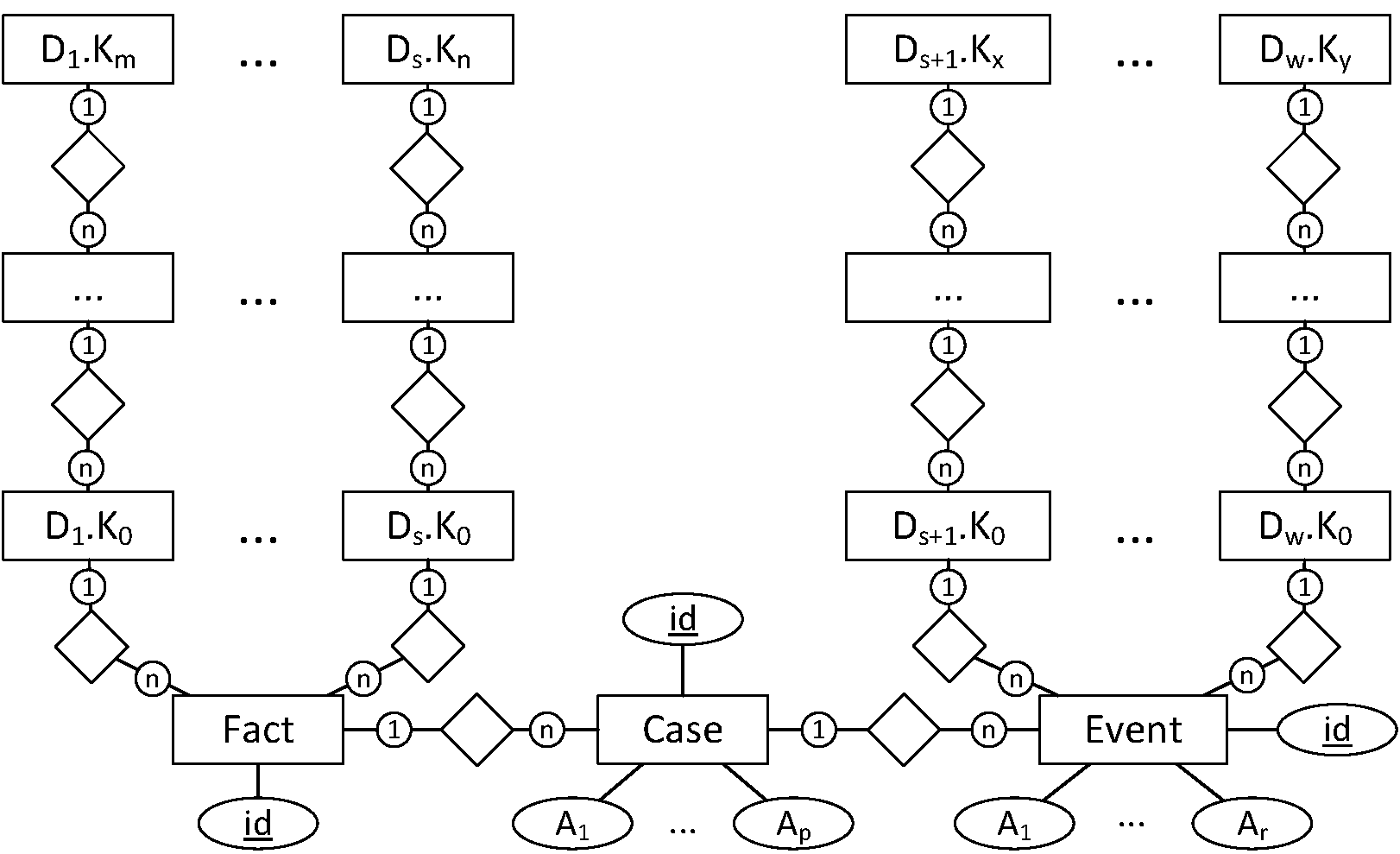
Similar to the snowflake schema, there is one table for each level of a dimension hierarchy and the tables of a dimension are connected by a 1:n foreign key relationship according to the hierarchy (e.g., tables D1.K0, ..., D1.Km). The Fact table references case dimension (i.e., each dimension representing a case attribute) by a foreign key reference to the table of its most fine-grained dimension level. Additionally, it also stores a unique id for the easy identification of cell of the data cube. The following table gives an overview of the columns of the Fact table.
| Column Name(s) | Type | Cardinality | Description |
|---|---|---|---|
| id | arbitrary | 1 | id of cell, must be unique |
| dim_1 ... dim_s | arbitrary | 1...* | foreign key to table of most fine-grained dimension level |
Using a foreign key, the cell id of the Fact table is referenced by the Case table which stores each single case as a row. Each tuple requires a mandatory unique id to identify the cases. Additionally, the Case table can also have an arbitrary number of additional attributes (A1, ..., Ap) to store the simple case attributes (i.e., all case attributes that are modeled as simple attributes). The simple attribute columns of the Case table may have arbitrary types. Tthe following table gives an overview of the columns of the Case table.
| Column Name(s) | Type | Cardinality | Description |
|---|---|---|---|
| id | arbitrary | 1 | id of case, must be unique |
| cell_id | arbitrary | 1 | foreign key reference to id column of Fact table |
| A_1 ... A_p | arbitrary | 0...* | columns for storing simple case attributes |
The Event table stores one event per row. Similar to the Case table, it references the tables of the most fine-grained dimension levels of all event dimensions (i.e., event attributes that are modeled as dimensions). The simple event attributes (i.e., event attributes modeled as simple attributes) are represented by an additional table column for each simple attribute (similar to Case table). The Event table also has a unique id and a foreign key reference to the id of the case that own the event. The following table summarizes the columns of the Event table.
| Column Name(s) | Type | Cardinality | Description |
|---|---|---|---|
| id | arbitrary | 1 | id of event, must be unique |
| case_id | arbitrary | 1 | foreign key reference to id column of Case table |
| dim_1 ... dim_w | arbitrary | 0..* | foreign key to table of most fine-grained dimension level |
| A_1 ... A_p | arbitrary | 0...* | columns for storing simple event attributes |
The structure of a dimension level table depends on whether the dimension level is the highest (i.e., most coarse-grained) level of the dimension. If it is not the highest dimension level, the table has a unique id column (used for referencing), a value column (holding a representation of the attribute's value), a description column (providing a more verbose textual description of the value), and a parent_id column holding a foreign key reference to the id of the parent dimension level value. The latter can be omitted for the highest level of a dimension, because this does not have a parent. The following table gives an overview of the columns of a dimension level table.
| Column Name(s) | Type | Cardinality | Description |
|---|---|---|---|
| id | arbitrary | 1 | id of dimension value, must be unique |
| value | arbitrary | 1 | representation of dimension level value |
| description | nvarchar/varchar2 | 1 | textual description of the dimension level vale |
| parent_id | arbitrary | 0...1 | foreign key reference to the table of parent dimension level, can be omitted if no parent exists |
Interactive PMCube Explorer provides a set of tools that support the creation of the data cube and the integration of data. With the Meta-Data Editor, you can create a meta-data file from scratch. The Data Integration Wizard helps you to create a data cube from an event log file and integrate its data into the cube. You can find the data integration tools on the Tools tab of the application's ribbon menu.